 Lucene.Net中,分词是核心库之一,当然,也可以将它独立出来。目前Lucene.Net的分词库很不完善,实际应用价值不高。唯一能用在实际场合的StandardAnalyzer类,效果也不是很好。内置在Lucene.Net里的分词都被放在项目的Analysis目录下,也就是Lucene.Net.Analysis命名空间下。分词类的命名一般都是以“Analyzer”结束,比如StandardAnalyzer,Sto..
Lucene.Net中,分词是核心库之一,当然,也可以将它独立出来。目前Lucene.Net的分词库很不完善,实际应用价值不高。唯一能用在实际场合的StandardAnalyzer类,效果也不是很好。内置在Lucene.Net里的分词都被放在项目的Analysis目录下,也就是Lucene.Net.Analysis命名空间下。分词类的命名一般都是以“Analyzer”结束,比如StandardAnalyzer,Sto..
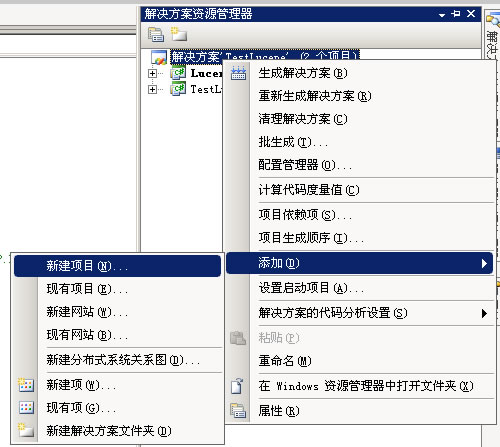
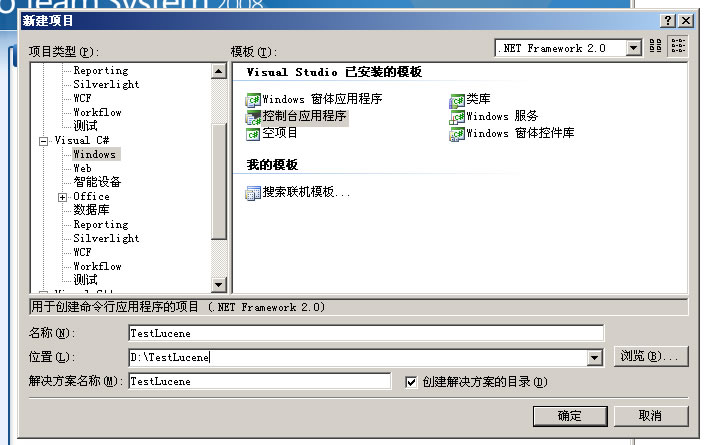 1、引用Lucene.Net类库 找到Lucene.Net的源代码,在“C#\src\Lucene.Net”目录。打开Visual Studio,我的版本是2008,而Lucene.Net默认的是2005。先创建一个项目,简单起见,创建一个C#控制台程序。图 1.1然后添加Lucene.Net进项目,如图 1.2 - 1.3。图 1.2图 1.3这个过程要进行一个VS2005到2008的转换。添加后,解决方案就有Lucene.Net项目了,..
1、引用Lucene.Net类库 找到Lucene.Net的源代码,在“C#\src\Lucene.Net”目录。打开Visual Studio,我的版本是2008,而Lucene.Net默认的是2005。先创建一个项目,简单起见,创建一个C#控制台程序。图 1.1然后添加Lucene.Net进项目,如图 1.2 - 1.3。图 1.2图 1.3这个过程要进行一个VS2005到2008的转换。添加后,解决方案就有Lucene.Net项目了,..
 引:这一篇关于搜索引擎中中文分词算法经典的文章,不敢独享。仅就对小几处的别字做了修改。中文分词算法 1.1.1 最大匹配法分词的缺陷尽管最大匹配法分词是常用的解决的方案,但是无疑它存在很多明显的缺陷,这些缺陷也限制了最大匹配法在大型搜索系统中的使用频率。最大匹配法的问题有以下几点:一、长度限制由于最大匹配法必须首先设定一个匹配..
补充禁止搜索引擎,一.什么是robots.txt文件?搜索引擎通过一种程序robot(又称spider),自动访问互联网上的网页并获取网页信息。您可以在您的网站中创建一个纯文本文件robots.txt,在这个文件中声明该网站中不想被robot访问的部分,这样,该网站的部分或全部内容就可以不被搜索引擎收录了,或者指定搜索引擎只收录指定的内容。二. robots.txt文..
作者:车东 发表于:2006-11-24 11:11 最后更新于:2007-04-15 19:04版权声明:可以任意转载,转载时请务必以超链接形式标明文章原始出处和作者信息及本版权声明。按照是否匿名和是否遵循robots.txt协议有4种蜘蛛:1 真名真姓,遵循robots.txt 协议。代表:GoogleBot BaiduSpider MSNBot Yahoo!Slurp 等2 真名真姓,不遵循robots.txt协议。代表:..
近期有很多站长咨询,怎样正确设置"robots.txt"文件。为了解决广大站长朋友们的疑问,我们对《Robots.txt 协议标准》进行了翻译,希望此篇译文能够帮助大家对"robots.txt"文件有更深的了解。Robots.txt 是存放在站点根目录下的一个纯文本文件。虽然它的设置很简单,但是作用却很强大。它可以指定搜索引擎蜘蛛只抓取指定的内容,或者是禁止搜索引..
最新V1.1版分词器,已更新。最新V1.1版分词器,已更新。1.修订了对数量次切分的BUG2.修订了对大文本切分时的重复输出BUG下载地址 Lucene中文分词器 V1.1 CSDN下载Lucene中文分词器 V1.1 Google 下载时间: 2006年12月21日 13:17最新V1.2版分词器,已更新。1.优化词典2.优化对人名,公司名,未知词汇切割算法下载地址Lucene中文分词器 V1.2 CSDN下..
引:这一篇关于搜索引擎中中文分词算法经典的文章,不敢独享。仅就对小几处的别字做了修改。中文分词算法 1.1.1 最大匹配法分词的缺陷尽管最大匹配法分词是常用的解决的方案,但是无疑它存在很多明显的缺陷,这些缺陷也限制了最大匹配法在大型搜索系统中的使用频率。最大匹配法的问题有以下几点:一、长度限制由于最大匹配法必须首先设定一个匹配..
补充禁止搜索引擎,一.什么是robots.txt文件?搜索引擎通过一种程序robot(又称spider),自动访问互联网上的网页并获取网页信息。您可以在您的网站中创建一个纯文本文件robots.txt,在这个文件中声明该网站中不想被robot访问的部分,这样,该网站的部分或全部内容就可以不被搜索引擎收录了,或者指定搜索引擎只收录指定的内容。二. robots.txt文..
作者:车东 发表于:2006-11-24 11:11 最后更新于:2007-04-15 19:04版权声明:可以任意转载,转载时请务必以超链接形式标明文章原始出处和作者信息及本版权声明。按照是否匿名和是否遵循robots.txt协议有4种蜘蛛:1 真名真姓,遵循robots.txt 协议。代表:GoogleBot BaiduSpider MSNBot Yahoo!Slurp 等2 真名真姓,不遵循robots.txt协议。代表:..
近期有很多站长咨询,怎样正确设置"robots.txt"文件。为了解决广大站长朋友们的疑问,我们对《Robots.txt 协议标准》进行了翻译,希望此篇译文能够帮助大家对"robots.txt"文件有更深的了解。Robots.txt 是存放在站点根目录下的一个纯文本文件。虽然它的设置很简单,但是作用却很强大。它可以指定搜索引擎蜘蛛只抓取指定的内容,或者是禁止搜索引..
最新V1.1版分词器,已更新。最新V1.1版分词器,已更新。1.修订了对数量次切分的BUG2.修订了对大文本切分时的重复输出BUG下载地址 Lucene中文分词器 V1.1 CSDN下载Lucene中文分词器 V1.1 Google 下载时间: 2006年12月21日 13:17最新V1.2版分词器,已更新。1.优化词典2.优化对人名,公司名,未知词汇切割算法下载地址Lucene中文分词器 V1.2 CSDN下..
