Web开发网 > Web后台开发 > lucene.net/分词技术
首页 上一页 [1] [2] 下一页 尾页 1/2页,每页显示30条,共37条相关记录

 Lucene.Net最高版本为3.0.3,并且apache已经不再提供Lucene.Net的更新,没仔细研究过Lucene.Net的所有版本,Lucene.Net3.0.3遍历TokenStream获取Token对象,已经和以前的版本有了很大的区别,很多方法都已经删除了或者过时。 以前版本的Lucene.Net从TokenStream中获取Token时调用Next方法就行了,源代码如下 public void Reusable..
Lucene.Net最高版本为3.0.3,并且apache已经不再提供Lucene.Net的更新,没仔细研究过Lucene.Net的所有版本,Lucene.Net3.0.3遍历TokenStream获取Token对象,已经和以前的版本有了很大的区别,很多方法都已经删除了或者过时。 以前版本的Lucene.Net从TokenStream中获取Token时调用Next方法就行了,源代码如下 public void Reusable.. 最近碰到公司要求修改搜索排序,要求和这篇文章说的差不多,Lucene关于实现Similarity自定义排序,非常感谢原作者原创文章,欢迎转载,请注明 Author:kernaling.wong#gmail.comhttp://kernaling-wong.iteye.com/blog/586043 职位搜索的结果排序应该是,相关度优先,然后才是职位的发布时间倒序.即如果关键字匹配是一定要全部命中了才会排在第..
最近碰到公司要求修改搜索排序,要求和这篇文章说的差不多,Lucene关于实现Similarity自定义排序,非常感谢原作者原创文章,欢迎转载,请注明 Author:kernaling.wong#gmail.comhttp://kernaling-wong.iteye.com/blog/586043 职位搜索的结果排序应该是,相关度优先,然后才是职位的发布时间倒序.即如果关键字匹配是一定要全部命中了才会排在第..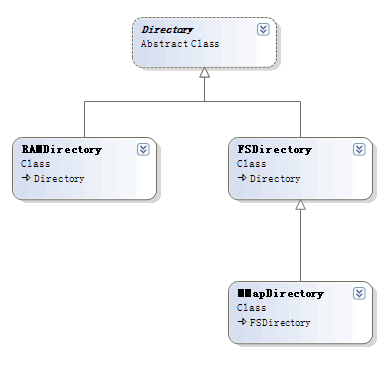 Lucene的文件系统分为内存和硬盘两个部分,文件逻辑组织方式暂且不提,本文将关注其物理结构,包括它在内存中如何存放,以及如何写入硬盘。目录一、相关类 1.1 Directory 1.2 IndexInput和IndexOutput 1.3 RAMFile二、索引概述 2.1 IndexOutput 2.2 RAMOutputStream和RAMFile 2.3 内存文件是如何写入硬盘的一、相关类1.1 Directory一个Director..
Lucene的文件系统分为内存和硬盘两个部分,文件逻辑组织方式暂且不提,本文将关注其物理结构,包括它在内存中如何存放,以及如何写入硬盘。目录一、相关类 1.1 Directory 1.2 IndexInput和IndexOutput 1.3 RAMFile二、索引概述 2.1 IndexOutput 2.2 RAMOutputStream和RAMFile 2.3 内存文件是如何写入硬盘的一、相关类1.1 Directory一个Director..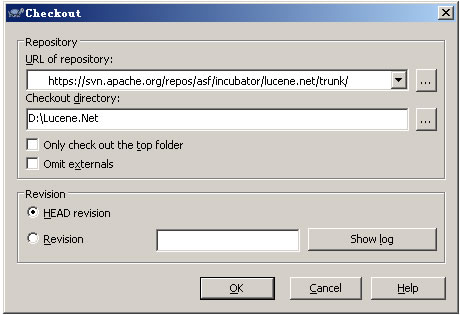 首先,你需要一个svn客户端。TortoiseSVN非常好用,可以从官方网站下载。下载地址:http://tortoisesvn.net/downloads。下载完成,就安装,需要重启电脑。然后在d盘下建立一个空文件夹,命名为Lucene.Net。打开文件夹,右键,则出现菜单。如图"附录一 1"。附录一 1发现多了两项,分别是SVN Checkout和TortoiseSVN。点“SVN Checkout”,出现“附..
首先,你需要一个svn客户端。TortoiseSVN非常好用,可以从官方网站下载。下载地址:http://tortoisesvn.net/downloads。下载完成,就安装,需要重启电脑。然后在d盘下建立一个空文件夹,命名为Lucene.Net。打开文件夹,右键,则出现菜单。如图"附录一 1"。附录一 1发现多了两项,分别是SVN Checkout和TortoiseSVN。点“SVN Checkout”,出现“附..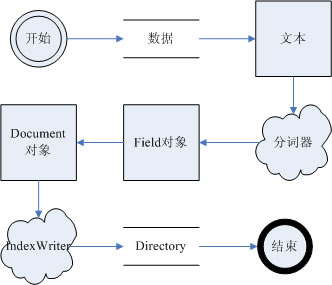 2、索引中用到的核心类在Lucene.Net索引开发中,用到的类不多,这些类是索引过程的核心类。其中Analyzer是索引建立的基础,Directory是索引建立中或者建立好存储的介质,Document和Field类是逻辑结构的核心,IndexWriter是操作的核心。其他类的使用都被隐藏掉了,这也是为什么Lucene.Net使用这么方便的原因。2.1 Analyzer前面已经对Analyzer进行..
2、索引中用到的核心类在Lucene.Net索引开发中,用到的类不多,这些类是索引过程的核心类。其中Analyzer是索引建立的基础,Directory是索引建立中或者建立好存储的介质,Document和Field类是逻辑结构的核心,IndexWriter是操作的核心。其他类的使用都被隐藏掉了,这也是为什么Lucene.Net使用这么方便的原因。2.1 Analyzer前面已经对Analyzer进行..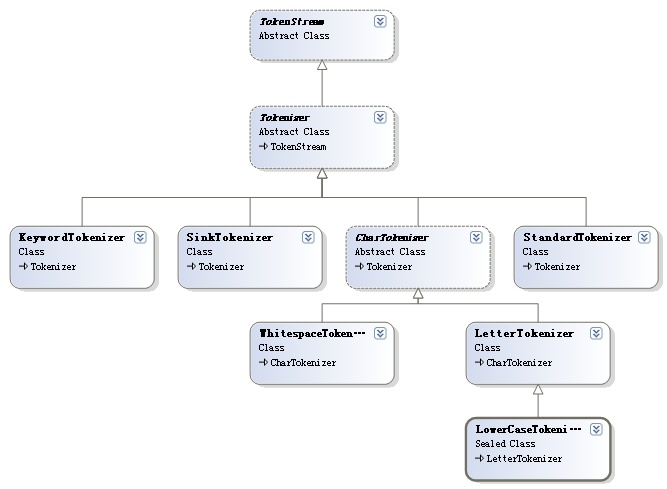 1.3 分词器结构1.3.1 分词器整体结构从1.2节的分析,终于做到了管中窥豹,现在在Lucene.Net项目中添加一个类关系图,把TokenStream和他的儿孙们统统拉上去,就能比较好的把握他们之间的关系。图 1.3.1.1如图1.3.1.1 就是他们的类关系图。看出如果要做一个分词器,最短的路,就是继承第二代,成为第三代。然后再写一个Analyzer的子类,专门用来做..
1.3 分词器结构1.3.1 分词器整体结构从1.2节的分析,终于做到了管中窥豹,现在在Lucene.Net项目中添加一个类关系图,把TokenStream和他的儿孙们统统拉上去,就能比较好的把握他们之间的关系。图 1.3.1.1如图1.3.1.1 就是他们的类关系图。看出如果要做一个分词器,最短的路,就是继承第二代,成为第三代。然后再写一个Analyzer的子类,专门用来做..